Deconstructing the Sub-500ms Voice Agent: A Technical Deep Dive into Real-Time AI Orchestration
Analysis | | Technology
The recent surge in funding for AI voice platforms, exemplified by ElevenLabs' monumental round, signals a market belief in conversational AI as the next dominant interface. Yet, beneath the polished abstractions of services like Vapi lies a labyrinth of engineering challenges that separate a functional demo from a fluid, human-like interaction. This analysis dissects the pursuit of sub-500 millisecond latency in custom-built voice agents—a benchmark where AI responses arrive faster than a human blink—exploring not just the "how," but the "why" this granular control matters for the future of the field.
Key Takeaways
- Latency is the Ultimate Metric: Achieving sub-500ms response times is less about raw model speed and more about sophisticated pipeline orchestration and geographic server placement.
- The Turn-Taking Dilemma: The core complexity of voice AI isn't understanding speech, but managing the continuous, real-time dance of listening and speaking without awkward pauses or interruptions.
- Abstraction vs. Control: While platforms offer simplicity, a custom-built orchestration layer can double performance, revealing that critical optimizations are often hidden by high-level APIs.
- Geography is Infrastructure: The physical location of STT, LLM, and TTS services relative to the user can contribute more to latency than the choice of AI model itself.
- A New Engineering Discipline Emerges: Building real-time voice agents requires a hybrid skillset merging audio engineering, distributed systems, and AI prompt design.
The Illusion of Simplicity: What Voice Platforms Hide
The proliferation of integrated AI voice agent platforms has created an illusion of solved complexity. Developers can provision a conversational interface with a few API calls, abstracting away the intricate symphony of components required. This mirrors the early days of cloud computing, where the ease of deployment often obscured understanding of underlying infrastructure. However, as evidenced by a recent independent build that achieved 400ms end-to-end latency—outpacing a comparable setup on a leading platform by a factor of two—the abstractions can also mask significant performance headroom. The trade-off is clear: convenience for control, and often, latency for simplicity.
This performance gap isn't incidental. Platform-level abstractions must cater to generalized use cases, implementing robust, fault-tolerant pipelines that prioritize stability over peak speed for any single interaction. They handle edge cases, scaling, and model fallbacks that a focused, custom implementation might initially bypass. The revelation that a dedicated developer can assemble a superior-performing pipeline in approximately a day and for a modest budget underscores a pivotal moment: the underlying technologies (STT, LLM, TTS) have matured enough that the orchestration logic itself becomes the primary differentiator, not just access to the models.
Beyond the Text Paradigm: The Real-Time Orchestration Challenge
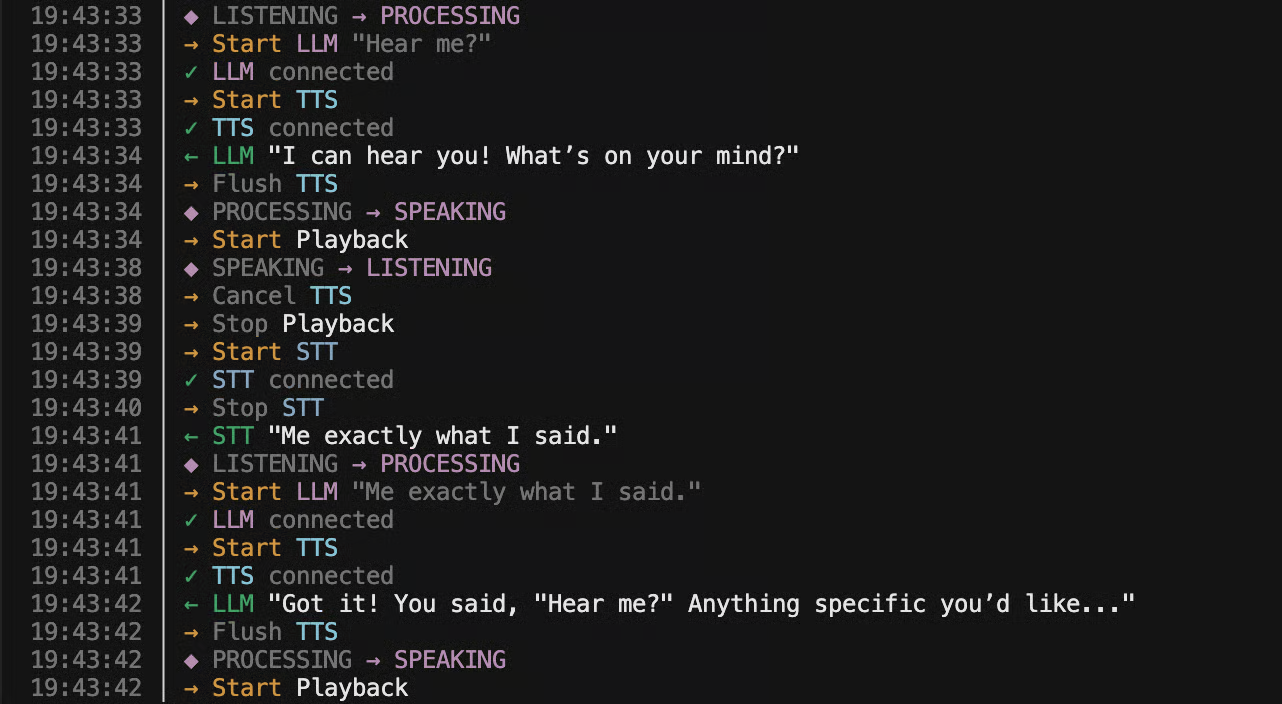
Text-based AI agents operate within a forgiving, turn-based paradigm. The user completes a thought, sends a message, and the system processes it at its own pace. The boundary of a "turn" is explicitly defined by a send button. Voice annihilates this comfort. Interaction becomes a continuous, real-time stream where the system must perpetually answer a critical question: Is the human currently speaking or listening?
This "turn-taking loop" is the heart of the difficulty. It requires instantaneous decision-making with imperfect data. When a user begins to speak, the agent must immediately—and gracefully—halt its own speech synthesis, cancel any ongoing LLM generation, and flush audio buffers to prevent cross-talk. Conversely, detecting the end of user speech is notoriously ambiguous. It is not a simple matter of silence detection. Natural human communication is filled with purposeful pauses, "ums," "ahs," coughs, and background noise. A system that jumps in too quickly feels interruptive and robotic; one that waits too long feels sluggish and inattentive.
This challenge connects to decades of research in dialogue systems and human-computer interaction. Modern solutions often employ a combination of Voice Activity Detection (VAD) with semantic endpointing, where the streaming Speech-to-Text (STT) output is analyzed in real-time by a secondary, lightweight model to predict whether a semantically complete unit of speech has been uttered. This moves the problem from an acoustic signal processing task to a shallow language understanding task, a subtle but profound shift enabled by the efficiency of contemporary small language models.
Anatomy of a 400ms Response: The Streaming Pipeline
The architectural blueprint for low-latency voice interaction is a carefully tuned streaming pipeline, where data flows like water through successive stages with minimal buffering. The goal is to begin the response before the user's final word is fully processed. The sequence is deceptively linear but must be executed in a highly overlapping, parallelized manner:
- Streaming Speech-to-Text (STT): Audio chunks are transcribed incrementally, sending partial results downstream the moment they are available, not waiting for a full sentence.
- LLM Streaming with Progressive Prompting: The language model begins generating a response based on the initial fragments of the user's transcribed speech. The prompt is dynamically updated as more text arrives, allowing the LLM to "think ahead" and form a coherent reply.
- Streaming Text-to-Speech (TTS): The first tokens of the LLM's streamed output are immediately sent to the TTS service, which starts synthesizing speech in parallel as the rest of the LLM's thought is still being generated.
This pipelining is what shaves off hundreds of milliseconds. However, its efficiency is brutally exposed to the laws of physics. The single largest external factor, often overlooked in purely algorithmic discussions, is network geography. If the STT service resides in one cloud region, the LLM in another, and the TTS in a third, the cumulative round-trip time for data traversing the globe can dwarf all processing delays. The breakthrough in the cited build likely involved colocating these services in a single, geographically optimal region or selecting providers with endpoints near each other, a tactical advantage a generalized platform cannot always guarantee for every user.
Two Critical Angles Beyond the Build
1. The Economic and Strategic Implications of De-Abstraction: The ability to build high-performance voice orchestration in-house carries significant business weight. For startups, it reduces dependency and recurring costs from third-party platforms. For larger enterprises, it mitigates strategic risk—voice interaction data is highly sensitive, and controlling the full stack ensures data governance and avoids vendor lock-in. As the core AI models themselves become increasingly commoditized (through offerings from OpenAI, Anthropic, Google, etc.), the proprietary value shifts to the orchestration intelligence—the unique logic for turn-taking, context management, and error recovery that defines the quality of the experience.
2. The Latency-Perception Threshold and the "Uncanny Valley" of Conversation: Psychological research into human conversation indicates that response delays beyond 500-600ms are perceptually registered as a lag, breaking the illusion of natural dialogue. Sub-500ms performance sits on the positive side of this cognitive threshold. But pushing latency ever lower introduces a new frontier: the potential for the agent to feel too fast, preemptively cutting off users or failing to mimic the natural rhythmic pauses of human speech. The next challenge isn't just speed, but appropriately timed speed—engineering conversational cadence and empathy into the timing logic itself.
The Road Ahead: From Prototype to Production
The journey from a one-day prototype to a production-grade system unveils a second layer of challenges. The initial build optimizes for the happy path. Production demands resilience: handling network dropouts, managing TTS audio artifacts when generation is cancelled mid-word, implementing fallback models when a primary service is slow, and designing context windows that persist across conversations without introducing latency. Furthermore, evaluating performance requires moving beyond single-metric latency to composite scores that weigh interruptibility, semantic accuracy, and audio naturalness.
The emergence of models like GPT-5.3 and Claude 4.6, with their improved reasoning speed and instruction-following, provides more capable "actors" for this orchestration layer. However, they do not solve the orchestration problem itself. The future of conversational AI may see the rise of specialized "conductor" models—small, ultra-fast networks trained explicitly to manage the state, timing, and routing of the larger, slower foundation models, specializing in the meta-task of conversation flow rather than content generation.
In conclusion, the pursuit of the sub-500ms voice agent represents more than a technical benchmark. It is a declaration that the most human of interfaces—spoken conversation—requires a new engineering discipline. It demands a synthesis of audio processing, real-time systems design, and AI integration, moving beyond the comfort of platform abstractions to reclaim control over the experience. As the underlying models continue to advance, the greatest innovations in voice AI may no longer come from the model makers alone, but from the architects who learn to conduct them in perfect, real-time harmony.